TL;DR
- source : https://www.ismll.uni-hildesheim.de/pub/pdfs/Rendle2010FM.pdf
- MF 일반화
데이터 형태
- supervised learning을 위해서 의 형태로 만들어야 함
- “User 5가 Item 4를 보고 Rating 4를 준 데이터”의 경우 다음과 같이 표현 가능 (전체 User 10명, 전체 Item 5개 가정)
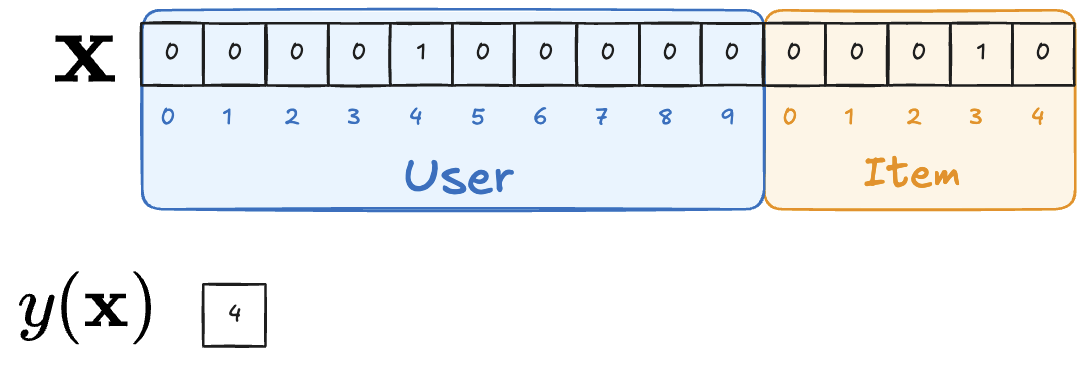
기존 모델들의 문제
- 기본적으로 추천시스템에서 활용하는 데이터는 많은 범주형 변수를 다루기 때문에 에 0 많은 sparse한 상태
- 크게 SVM 모델과 Factorization 모델들이 있는데 각각 한계가 있음
SVM models
- Linear Kernel
- user ,item의 bias만 고려한 아주 기본적인 CF 모형으로 생각할 수 있음
- 매우 간단해서 sparse해도 추정 잘되긴하는데 당연히 성능은 안좋음
- Polynomial Kernel
- : symmetric matrix
- 모든 상호작용 파라미터 를 독립으로 취급
- 가 업데이트되려면 User u가 Item i를 평가한 훈련데이터가 있어야 함
- 따라서 Sparse한 상황에서 non-linear 상호작용을 학습하기가 어려움
Factorization models
- Sparse한 User - Item Interaction 행렬이 input이라서 일반적인 실수 feature vector 사용할 수 없음
- User, Item 이외에 새로운 feature를 넣고 싶으면 번거로움
Factorization Machine
- high sparsity 에서도 믿을만한 파라미터 추정이 가능하며 SVM처럼 일반적인 predictor로 사용가능한 모델
장점
- Sparse한 데이터에서 non-linear 관계 파라미터 추정 가능
- polynomial kernel SVM 처럼 모든 nested variable interaction 모델링을 할 수 있는 것은 동일
- 하지만 scalar 파라미터 를 두는 것이 아닌 MF처럼 벡터의 내적으로 표현한 ‘factorized parameterization’ 사용
- Linear time에 계산가능하며 linear number of parameter 보유
- 임의의 실수 feature vector 사용 가능
- feature vector 잘 조정하면 다양한 모델 표현 가능하며 실제로 여러 CF 모델을 일반화한 모델
예시 데이터 형태
-
7개의 데이터
- #1 : User ‘B’가 Movie ‘SW’를 Time ‘5’에 시청 → 별점 4
- #2 : User ‘B’가 Movie ‘ST’를 Time ‘8’에 시청 → 별점 5
- #3 : User ‘C’가 Movie ‘TI’를 Time ‘9’에 시청 → 별점 1
- #4 : User ‘C’가 Movie ‘SW’를 Time ‘12’에 시청 → 별점 5
- #5 : User ‘A’가 Movie ‘TI’를 Time ‘13’에 시청 → 별점 5
- #6 : User ‘A’가 Movie ‘NH’를 Time ‘14’에 시청 → 별점 3
- #7 : User ‘A’가 Movie ‘SW’를 Time ‘16’에 시청 → 별점 1
-
기본적으로 User, Item은 사용하고, 그 외의 Auxiliary Features는 자유롭게 사용 → 이것이 FM의 장점
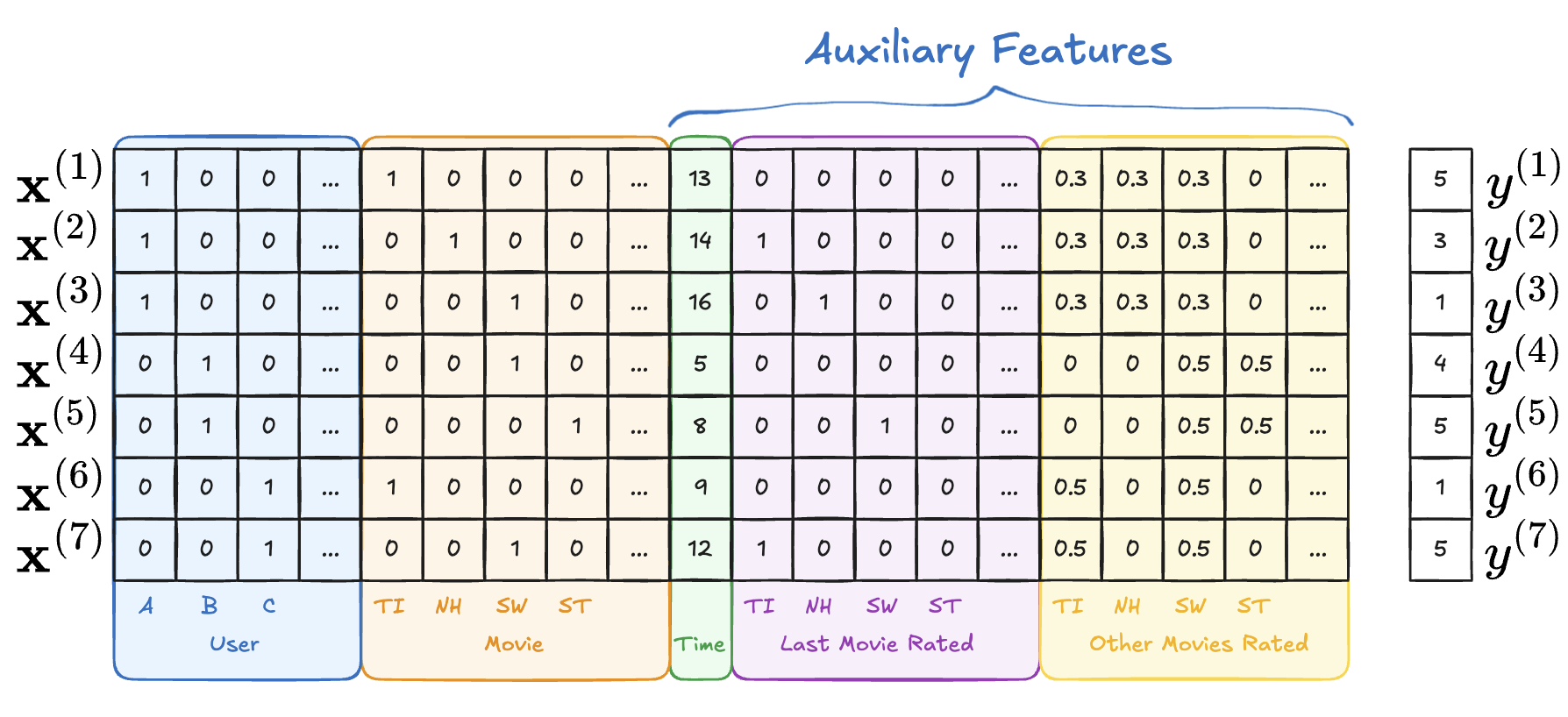
- User: one hot encoded 유저
- Movies: 해당 유저가 평가한 one hot encoded 영화
- Time: 데이터 들어온 시점
- Other Movies rated: 그 유저가 본 모든 영화 표시
- Last Movie rated: 직전에 평가한 영화
2-way Factorization Model
- Notation
- : data sample의 feature 개수. 총 interaction 데이터 개수가 아니고 위의 그림에서 column의 길이
- : ith feature
- 추정해야할 파라미터는
- : global bias
- : i 번째 변수의 strength
- : ith, jth 변수간의 interaction → sparsity하에서 고차원 상호작용 파라미터 추정의 핵심
- : dot product
- 2-way FM (d=2)은 모든 single, pairwise interaction 잡아냄
Training 예시 : 전체 User 10명, Item 5개인 상황에서 User ID 5가 Item ID 4에 Rating 4를 부여
- User와 Item 만 활용하는 간단한 예시
- Training 과정
- Interaction 데이터를 위의 그림 형태로 수정
- 임의로 초기화된 파라미터들로 계산
- 실제 Rating과의 차이로 파라미터 업데이트
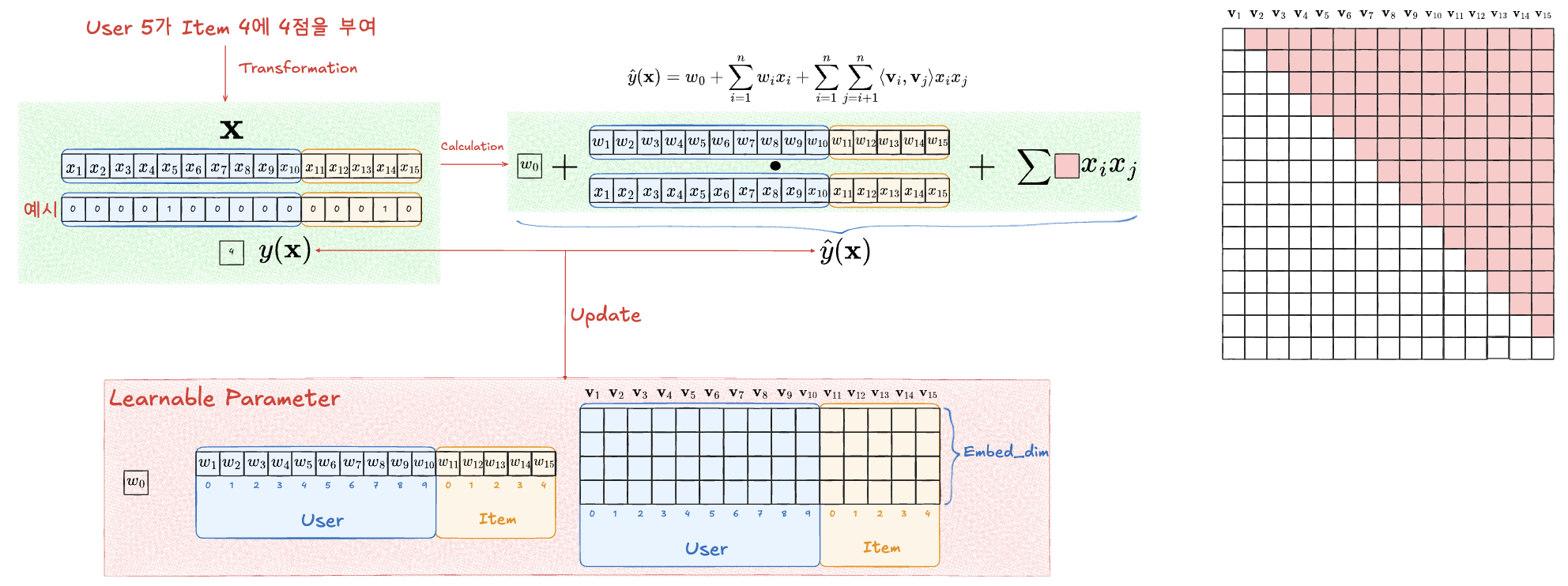
- 실제로 위의 예시처럼 User, Item 2가지 feature만 이용해서 FM을 하는 것은 Matrix Factorization과 동일
- polynomial 항에서 만 1이고 나머지는 모두 0

- polynomial 항에서 만 1이고 나머지는 모두 0
왜 Sparse한 경우 더 유리할까?
- FM에서는 factorization을 통해 를 공유함으로써 파라미터의 독립성을 제거 → sparse함에도 interaction을 추정할 수 있는 것
예시 : User-Item만 활용 : User 100명, Item 20개, 임베딩 차원 = 4
- 학습해야하는 파라미터 (2차식만)
- FM : →
- SVM : →
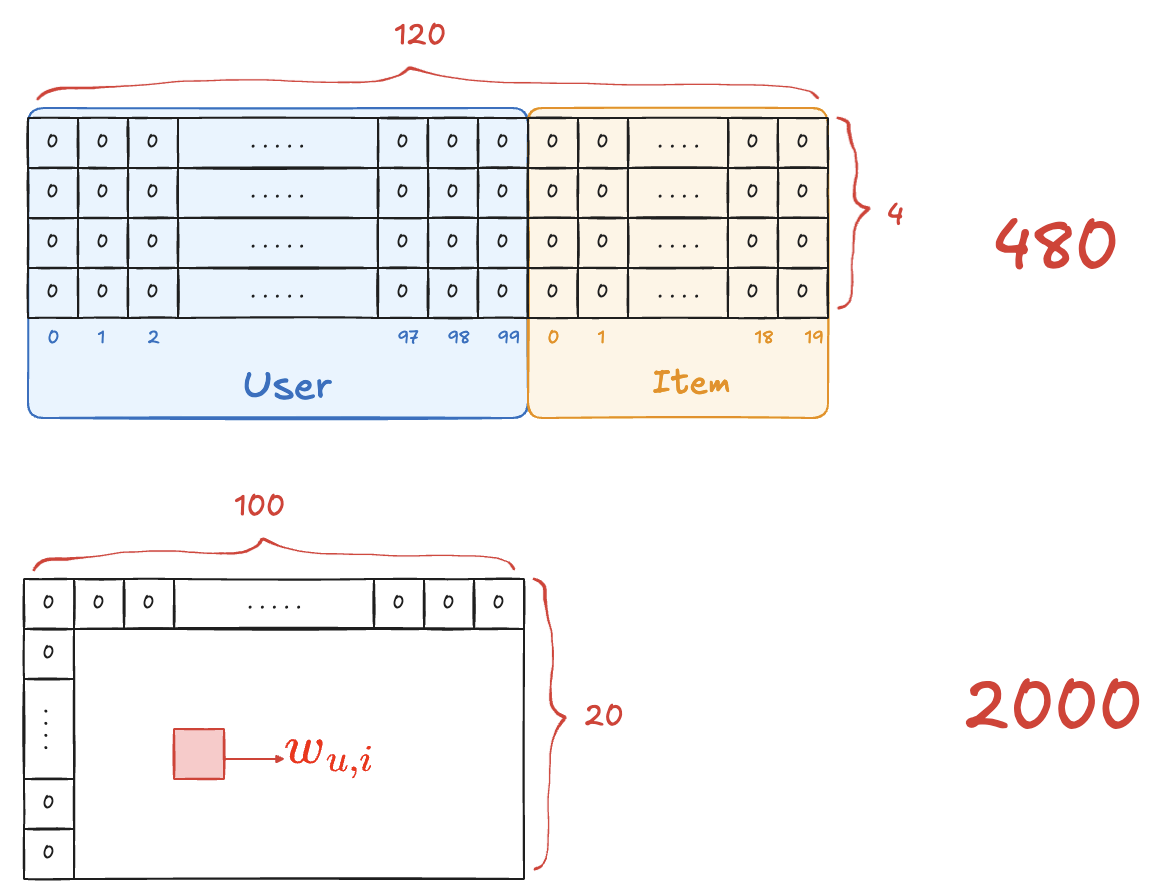
- 학습 과정 : (user 5, item 4) 관측 예시
- FM → 둘 다 갱신 → (user 5, 다른 item), (다른 user, item 4) 예측에 반영
- SVM → 만 갱신
Linear Complexity
- Pairwise Interaction의 시간복잡도는 으로 보이지만 실제로는 에 계산 가능
Training : 위에서 으로 변형한 식을 미분해서 SGD
코드
Info
- 참고 : https://github.com/rixwew/pytorch-fm/blob/master/torchfm/model/fm.py#L7
- User, Item 이외의 Auxiliary를 추가할 수 있는데 아마 one-hot encoding되는 것만 가능한 듯
import torch
from torchfm.layer import FactorizationMachine, FeaturesEmbedding, FeaturesLinear
class FactorizationMachineModel(torch.nn.Module):
"""
A pytorch implementation of Factorization Machine.
Reference:
S Rendle, Factorization Machines, 2010.
"""
def __init__(self, field_dims, embed_dim):
super().__init__()
self.embedding = FeaturesEmbedding(field_dims, embed_dim)
self.linear = FeaturesLinear(field_dims)
self.fm = FactorizationMachine(reduce_sum=True)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = self.linear(x) + self.fm(self.embedding(x))
return torch.sigmoid(x.squeeze(1))
class FeaturesEmbedding(torch.nn.Module):
def __init__(self, field_dims, embed_dim):
super().__init__()
self.embedding = torch.nn.Embedding(sum(field_dims), embed_dim)
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
torch.nn.init.xavier_uniform_(self.embedding.weight.data)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
return self.embedding(x)
class FeaturesLinear(torch.nn.Module):
def __init__(self, field_dims, output_dim=1):
super().__init__()
self.fc = torch.nn.Embedding(sum(field_dims), output_dim)
self.bias = torch.nn.Parameter(torch.zeros((output_dim,)))
self.offsets = np.array((0, *np.cumsum(field_dims)[:-1]), dtype=np.long)
def forward(self, x):
"""
:param x: Long tensor of size ``(batch_size, num_fields)``
"""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
return torch.sum(self.fc(x), dim=1) + self.bias
class FactorizationMachine(torch.nn.Module):
def __init__(self, reduce_sum=True):
super().__init__()
self.reduce_sum = reduce_sum
def forward(self, x):
"""
:param x: Float tensor of size ``(batch_size, num_fields, embed_dim)``
"""
# O(kn^2) -> O(kn)
square_of_sum = torch.sum(x, dim=1) ** 2
sum_of_square = torch.sum(x ** 2, dim=1)
ix = square_of_sum - sum_of_square
if self.reduce_sum:
ix = torch.sum(ix, dim=1, keepdim=True)
return 0.5 * ix