TL;DR
- source : https://arxiv.org/pdf/1708.05031
- Deep Learning + Collaborative Filtering
- Contributions
- neural network로 CF를 하는 NCF 제안
- 기존의 Matrix Factorization은 NCF로 설명 가능하고 고차원의 non-linearity를 모델링하기 위해 MLP 사용
기존 MF 한계
- interaction을 user와 item의 latent vector 로 추정
- 독립 · 동일 가중치 가정
- 각 차원은 서로 영향 없음
- 모든 차원이 같은 힘으로 결과에 기여
- 표현력 한계
- 내적은 선형 관계만 담음 → 복잡한 “조건부 선호”나 비선형 패턴을 담기 어려움
- 기존 유저 간 거리관계를 만족시키면 새 유저 추가 시 다른 거리 요구를 동시에 만족 못함
- 차원 늘리기 문제
- K를 크게 하면 과적합 위험 증가
- 학습 데이터 적은 유저 · 아이템에 취약
- 대칭 · 스케일 혼합
- 벡터 크기와 방향이 뒤섞여 해석 어려움
- 유저와 아이템 사이 본질적 비대칭 반영 어려움
- 희소 · 편향 데이터 취약
- 관측 로그만 사용해 노출 편향 교정 힘듦
- 저빈도 아이템은 정보 부족으로 부정확
Neural Matrix Factorization (NeuMF)
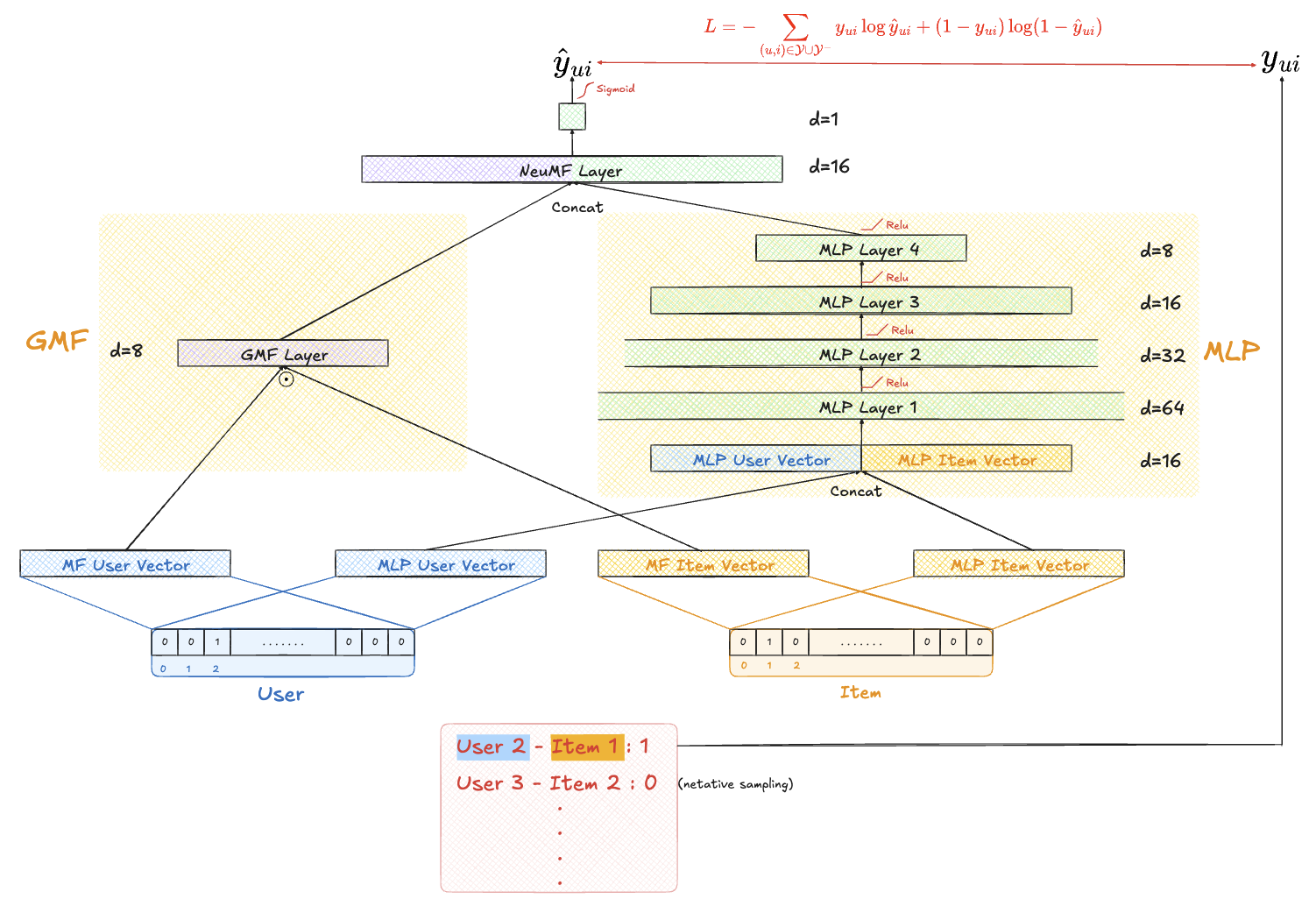
기본 세팅
- Implicit feedback 가정
- : 사용자가 아이템 i를 클릭·재생·구매 등 어떤 방식으로든 접촉했다는 사실만 의미
- : ① 노출됐지만 관심 없어 클릭 안 함 ② 애초에 노출되지 않음 (추천·검색 결과에 없었음)
- 따라서 Negative Feedback이 부족해서 문제 생길 수 있음
- 플랫폼은 클릭·구매 등 행동이 있는 쌍만 기록 → 대부분 1
- 노출·무관심·싫어요를 구분할 명시적 항목이 없음
- 추천·검색 알고리즘이 이미 인기 아이템을 더 많이 노출 → 미노출 아이템은 0으로 남음
- 따라서 0 중 상당수가 알려지지 않은 잠재적 양호(positive)
- 중 1은 희소하지만 학습 단계에서는 “positive 표본”만 확실, 나머지는 애매
- 모델이 학습 과정에서 ‘싫어함’ 신호를 거의 받지 못해 over-generalization 위험
- 플랫폼은 클릭·구매 등 행동이 있는 쌍만 기록 → 대부분 1
Loss : Implicit feedback → Binary cross entropy loss
- : 관찰된 interaction
- : 관찰되지 않은 interaction
학습 과정에서 어떻게 적용?
- 일반적으로 관찰되지 않은 interaction의 개수가 훨씬 많음
- 매 iteration마다 관찰된 interaction와 비율을 맞춰서 uniform하게 샘플링해서 학습에 사용
def get_train_instances(train, num_negatives): user_input, item_input, labels = [],[],[] num_users = train.shape[0] for (u, i) in train.keys(): # positive instance user_input.append(u) item_input.append(i) labels.append(1) # negative instances for t in xrange(num_negatives): j = np.random.randint(num_items) while train.has_key((u, j)): j = np.random.randint(num_items) user_input.append(u) item_input.append(j) labels.append(0) return user_input, item_input, labels
- item 인기도 기반으로 non-uniform sampling도 가능
- 실제로 노출이 많이 되었지만 (인기가 높아서) 선택이 안된 interaction을 학습에 더 자주 사용
Pre-training
- GMF 부분과 MLP 부분으로 각각 모델 만들어서 학습
- 이후 NeuMF Layer에서 hyperparameter weight 줘서 concat
Evaluation : leave-one-out
- user의 가장 마지막 interaction 1개 + user와 상호작용 없던 item 100개 샘플링해서 총 101개 item으로 Hit ratio, NDCG 검증